如何在 AWS Lambda 上部署 Python ETL 管道(無伺服器架構)
專業實作指南:設計、部署與優化 AWS Lambda ETL 管道
理解無伺服器 ETL
ETL(抽取、轉換、載入)是現代資料工程的核心。在傳統環境中,ETL 常依賴大型伺服器、叢集或專用資料管道框架。隨著無伺服器運算的興起,特別是 AWS Lambda,企業能夠在不管理伺服器的情況下執行 ETL 工作,使資料團隊專注於邏輯開發而非基礎設施管理。
無伺服器 ETL 意味著管道可以自動擴展、按需運行,並且僅在執行時產生費用。搭配 Amazon S3、Step Functions 與 EventBridge,能設計出成本效益高、可維護性強的管道。
無伺服器 Python ETL 架構
良好設計的無伺服器 ETL 管道通常包含下列元件:
- 資料來源:上傳至 S3 的檔案、Kinesis 串流資料或 API。
- Lambda 函數:使用 Python 進行資料抽取與轉換。
- 中繼儲存:S3 用於暫存原始與轉換資料。
- 資料倉儲或資料庫:Amazon Redshift、RDS 或 DynamoDB。
- 流程編排:Step Functions 或 EventBridge 用於管道執行協調。
💡 小提示: 對於大型資料轉換,可考慮將 Lambda 與 AWS Glue 結合,或僅使用 Lambda 作為觸發器。
建立 AWS 環境
在撰寫 Python 代碼前,需要先準備環境:
- 建立 S3 桶以存放原始及處理後資料。
- 為 Lambda 定義最小權限 IAM 角色。
- 安裝 AWS CLI 並配置憑證。
- 選擇部署框架(AWS SAM、CDK 或 Serverless Framework)。
# 配置 AWS CLI
aws configure
# 輸入 Access Key, Secret, Region 以及預設輸出格式
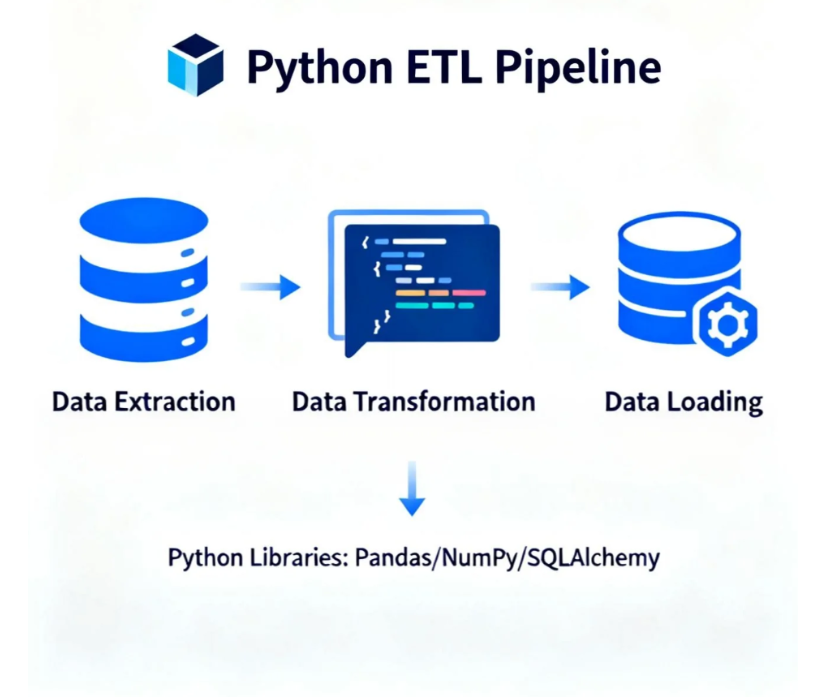
建構 Python ETL 管道
抽取(Extract)
在此階段,管道連接來源系統並擷取原始資料。常見例子是從 S3 下載 CSV 檔案。
import boto3
import pandas as pd
s3 = boto3.client('s3')
bucket_name = 'my-etl-bucket'
file_key = 'raw/data.csv'
response = s3.get_object(Bucket=bucket_name, Key=file_key)
raw_data = pd.read_csv(response['Body'])
轉換(Transform)
資料轉換包括清理、標準化、資料增強及驗證。Lambda 適合輕量處理,但大型轉換可能超過 Lambda 記憶體或執行時間限制。
# 清理與轉換資料
def transform(df):
df = df.dropna()
df['date'] = pd.to_datetime(df['date'])
df['amount'] = df['amount'].astype(float)
return df
processed_data = transform(raw_data)
載入(Load)
轉換後的資料可儲存回 S3(Parquet 格式)或直接載入資料庫。
# 儲存為 Parquet 並上傳至 S3
output_key = 'processed/data.parquet'
processed_data.to_parquet('/tmp/temp.parquet', index=False)
s3.upload_file('/tmp/temp.parquet', bucket_name, output_key)
部署至 AWS Lambda
Python 代碼完成後,可打包部署至 Lambda。若使用 Pandas 等依賴,需使用 Lambda Layers 或容器映像。
使用 AWS SAM
AWS Serverless Application Model (SAM) 可簡化部署,於 template.yaml 定義資源:
Resources:
ETLFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ./src
Handler: app.lambda_handler
Runtime: python3.9
MemorySize: 1024
Timeout: 900
Policies:
- AmazonS3FullAccess
部署指令:
sam build
sam deploy --guided
流程編排與觸發
無伺服器 ETL 需編排來處理依賴與時間控制。常見觸發方式:
- S3 觸發:檔案上傳時自動執行 ETL。
- EventBridge:排程定期執行作業。
- Step Functions:將多個 Lambda 函數組合成工作流程。
# EventBridge 範例規則:每日執行
aws events put-rule \
--name DailyETL \
--schedule-expression "cron(0 2 * * ? *)"
安全性與權限
資料管道的安全性至關重要,建議:
- 使用最小權限 IAM 角色。
- 敏感資訊存於 AWS Secrets Manager,而非環境變數。
- 啟用 S3 桶與靜態資料加密。
- 透過 VPC 連接私有資料來源。
監控、日誌與錯誤處理
監控確保 ETL 管道運行健康。AWS 提供原生觀測工具:
- CloudWatch Logs:捕獲詳細執行日誌。
- CloudWatch Metrics:監控呼叫次數、執行時間與錯誤。
- Dead Letter Queues (DLQ):捕獲失敗事件便於除錯。
- SNS 通知:管道失敗時警示團隊。
# 日誌範例
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.info("ETL 作業啟動")
效能調校與成本優化
Lambda 成本效益高,但仍需優化以確保可擴展性:
- 調整記憶體與逾時設定。
- 使用 Parquet 與分割以提高儲存效率。
- 利用 Lambda Layers 共用依賴。
- 透過預配置併發保持函數熱啟動,減少冷啟動延遲。
⚡ 專業建議: 測試不同配置以取得執行時間與記憶體之間的最佳平衡,達到成本最優化。
限制與不適用場景
AWS Lambda 強大,但非萬能。以下情況應考慮替代方案:
- 單次執行需超過 15 分鐘。
- 資料量超過 Lambda 可用記憶體(最多 10 GB 臨時儲存)。
- 複雜依賴超過部署包大小限制。
- 需要近即時大規模串流(考慮 Kinesis 或 EMR)。
結語
將 Python ETL 管道部署到 AWS Lambda,可享受無伺服器架構的優勢:降低營運負擔、具可擴展性、成本效益高。透過精心設計架構、保障資料安全、優化效能,無論是小型專案或企業級資料需求都能滿足。結合 Step Functions、EventBridge 與 Secrets Manager,Lambda 成為現代 ETL 的強大基礎。
是否選擇無伺服器,應依據資料需求、轉換複雜度與成本結構決定。對多數企業而言,AWS Lambda 在 ETL 工作負載中提供了簡單與擴展性間的最佳平衡。