為什麼需要 Prompt Parsing Pipeline?
在沒有 Pipeline 的情況下,Prompt 存在以下問題:
- 需求表述模糊 → 模型容易誤解
- 自然語言不具一致性 → 格式難以解析
- 模型高變異性 → 沒有 deterministic 行為
- 無法支援大規模或複雜任務
❌ 傳統做法(不穩定)
“請幫我把這段文字整理成重點。”
模型可能會:
- 少講部分重點
- 加入不存在的內容
- 格式亂掉
- 每次輸出都不一致
✔ 工程化做法(穩定)
使用 Pipeline 確保:
- 任務意圖明確
- Prompt 按模板生成
- 輸出強制為 JSON
- 程式可做 Schema 驗證
- 失敗時自動回修
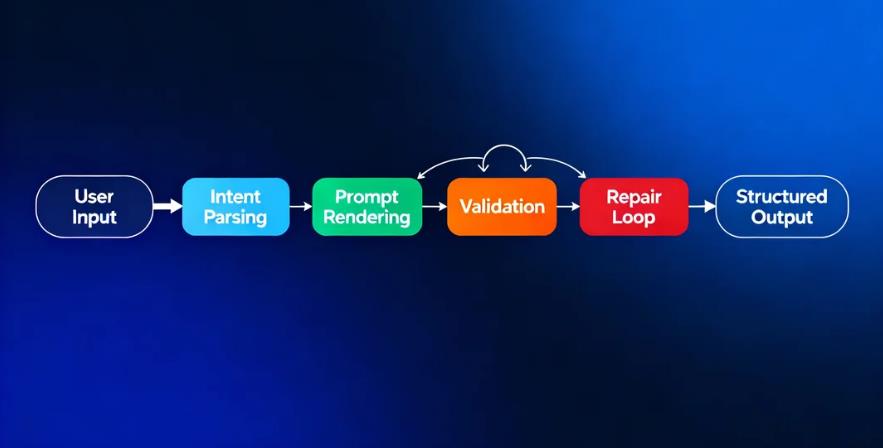
🔧 二、Prompt Parsing Pipeline 架構概覽
以下是整體流程圖(Mermaid):
flowchart TD
A[User Input<br>自然語言輸入] --> B[Intent Normalization<br>意圖標準化]
B --> C[Prompt Template Rendering<br>提示模板渲染]
C --> D[Safety & Consistency Rewriting<br>安全與一致性增強]
D --> E[LLM Invocation<br>呼叫大語言模型]
E --> F[Output Validation<br>結構化輸出驗證]
F -->|失敗| G[Error Correction Loop<br>自動修復]
G --> E
F --> H[Post-processing<br>後處理/任務執行]
🧩 三、六大關鍵步驟(工程級解析)
1️⃣ User Intent Normalization(使用者意圖標準化)
使用者輸入常常帶有:
- 模糊需求
- 不必要的背景敘述
- 多個混雜目的
這一步的目標是把自然語言轉成結構化意圖資料。
📌 Prompt 示例(可直接用)
請將使用者輸入的內容標準化,並僅輸出 JSON:
{
"goal": "主要任務",
"constraints": ["限制條件"],
"key_parameters": {}
}
使用者輸入:{{ user_input }}
📌 Python 代碼
intent_prompt = f"""
Normalize the user's intent. Output JSON only:
{{
"goal": "",
"constraints": [],
"key_parameters": {{}}
}}
User input: {user_input}
"""
2️⃣ Prompt Template Rendering(提示模板渲染)
不要讓 Prompt 寫死,應該是參數化模板。
📌 Jinja2 示例
from jinja2 import Template
template = Template("""
你是一位精通 Python 的資深技術助手。
任務說明:
{{ goal }}
限制條件:
- {{ constraints | join("\\n- ") }}
使用者提供的參數(JSON):
{{ params | tojson }}
請依上述資訊產生輸出。
""")
final_prompt = template.render(
goal=intent["goal"],
constraints=intent["constraints"],
params=intent["key_parameters"]
)
3️⃣ Safety & Consistency Rewriting(安全與一致性增強)
加入明確的格式與安全規則:
- Only respond in JSON
- 若資訊不足,回傳 “INSUFFICIENT_DATA”
- 避免幻想內容
- 避免自行補充未提供資訊
📌 可複用的安全提示段落
若你不確定答案,請回覆 "INSUFFICIENT_DATA"。
請務必以合法 JSON 格式回覆,且不得加入任何其他說明文字。
4️⃣ LLM Output Validation(輸出驗證)
絕對不要相信 LLM 會乖乖輸出 JSON。
必須做 Schema 驗證。
📌 pydantic 驗證範例
from pydantic import BaseModel, ValidationError
class ModelOutput(BaseModel):
title: str
steps: list[str]
complexity: int
try:
result = ModelOutput.model_validate_json(llm_output)
except ValidationError as e:
error_info = str(e)
# 進入修復流程
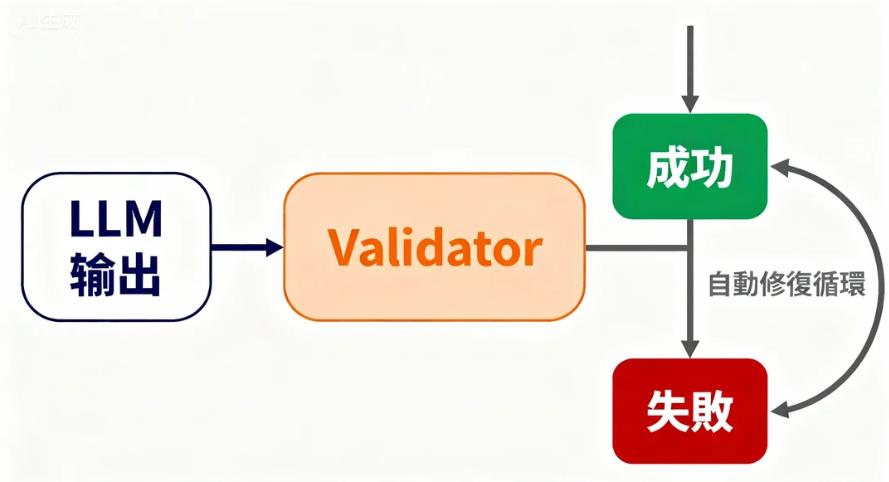
5️⃣ Error Correction Loop(自動修復迴圈)
又稱 Self-Healing Prompt Loop。
當模型輸出格式錯誤時,系統會:
- 捕捉錯誤
- 將錯誤訊息回傳給模型
- 要求模型修正
- 再次驗證
📌 修復 Prompt
repair_prompt = f"""
你的上一個輸出未能通過結構化驗證,錯誤如下:
{error_info}
請修正並重新輸出合法 JSON,不得加入除 JSON 以外的文字。
"""
6️⃣ Final Post-processing(後處理)
這一步是讓結果真的用到工程流程中。如:
- 移除空欄位
- JSON 轉 Python dict
- 整理為 Python 代碼
- 傳回前端或下個 Agent
- 控制 deterministic 行為
🏗 四、三個工程級落地案例
📘 案例 1:自然語言 → Python 腳本
流程:
使用者描述需求
→ intent parsing
→ 渲染模板
→ 輸出 Python 代碼片段
→ pydantic 驗證
可應用於:
- 自動生成 ETL script
- 自動資料處理
- 自動測試案例
📄 案例 2:文件資訊抽取(Information Extraction)
使用強制 JSON Schema,可以實作:
- 法律條款抽取
- 合約重點摘要
- 醫療報告 key-value 解析
- 財報資訊標準化
這類任務不做 Pipeline 幾乎無法落地。
🤖 案例 3:ChatGPT 風格「智能 Agent Prompt Builder」
讓 Agent 根據任務自動生成 Prompt:
- 意圖解析
- 選擇技能模組(Search / Code / 数据分析)
- 合成多段提示(System + Task + Format)
- 保證結果可解析
這就是許多「AI 助理」、「智慧客服」背後必備的機制。
📚 五、Prompt 不是『寫得像人話』,而是『寫得像工程』
要打造穩定、可預期的大語言模型系統,
重點不是靠靈感寫提示,而是:
- 流程化(Pipeline)
- 參數化(Templates)
- 結構化(Schema)
- 可驗證(Validation)
- 可修復(Self-Healing)
這樣才能讓 LLM 成為真正可控的軟體組件,而不是一個不可預期的黑盒子。