

ETL 與 ELT:用簡單的 Python 範例解釋兩者差異
前言
在現今以資料為驅動的世界中,企業越來越依賴大規模資料處理來推動洞察、流程自動化與決策。兩種常見的資料管線設計思維是 ETL(Extract, Transform, Load) 與 ELT(Extract, Load, Transform)。雖然這兩個縮寫看似相似,但實際上代表著截然不同的工作流程與優缺點。了解 ETL 與 ELT,對資料工程師、分析師,甚至商業決策者而言,都是建立高效資料策略的關鍵。
本文將深入比較 ETL 與 ELT 的概念,說明它們在架構與運作上的不同,分析各自的優勢與限制,並以簡單的 Python 範例進行說明。閱讀完後,你將能理解何時應該使用 ETL、何時適合 ELT,以及如何在實務中靈活應用。
什麼是 ETL 與 ELT?
ETL(Extract, Transform, Load)
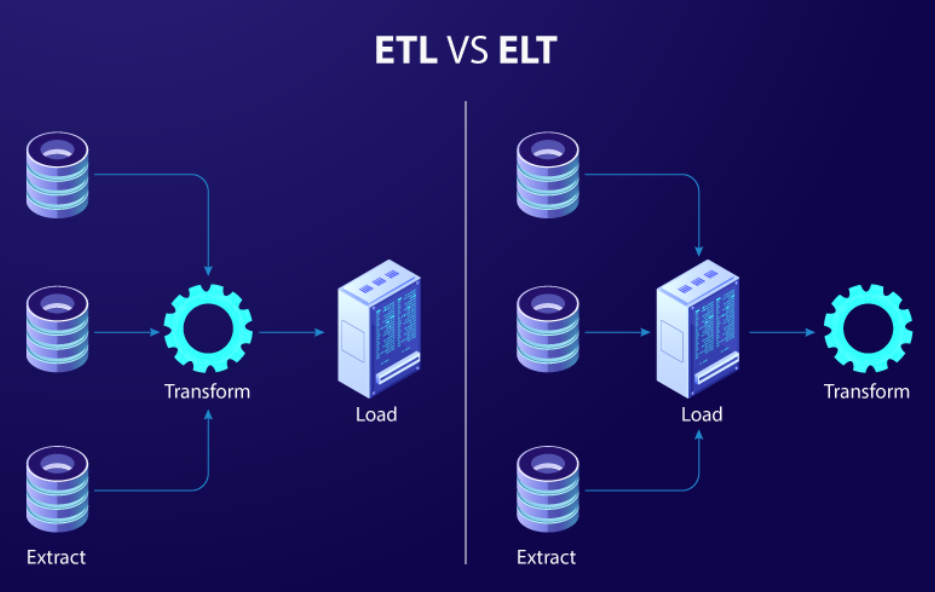
ETL 是一種傳統的資料整合流程。它先從資料來源中 擷取 資料(Extract),再於外部環境中進行 轉換(Transform),最後 載入(Load)至目標系統,如資料倉儲(Data Warehouse)。在過去,ETL 常被應用於本地端伺服器與早期的商業智慧系統中,轉換步驟通常在獨立的 ETL 伺服器中進行。
ELT(Extract, Load, Transform)
ELT 則將後兩個步驟對調。資料會先被 擷取 後立即 載入 至目標系統(通常是雲端資料倉儲或資料湖),接著在系統內部進行 轉換。這種方法充分利用現代雲端平台(如 BigQuery、Snowflake、Amazon Redshift)的運算能力,因此在雲端資料工程領域中越來越受歡迎。
架構上的差異
雖然 ETL 與 ELT 的最終目標都是生成乾淨可用的資料,但它們的架構截然不同:
- ETL: 轉換在載入之前完成。通常使用外部處理引擎,如 Apache Spark 或 Python 腳本。
- ELT: 轉換在載入之後於資料倉儲內部進行,依賴 SQL 或內建函式完成。
當需要進行複雜邏輯或自訂運算時,ETL 是較佳選擇;而當資料規模龐大、需即時處理或結構多樣時,ELT 的彈性與擴展性則更具優勢。
優點與缺點
ETL 的優點
- 在載入前已預先處理資料,可節省儲存與計算成本。
- 支援舊式系統與本地端架構。
- 適用於結構化資料與批次處理。
ETL 的缺點
- 面對大型資料集時處理時間較長。
- 需要額外的轉換基礎設施。
- 對半結構化或非結構化資料的彈性不足。
ELT 的優點
- 可充分利用雲端資料倉儲的彈性與運算能力。
- 面對龐大資料時載入速度更快。
- 支援即時與近即時的資料分析。
ELT 的缺點
- 原始資料可能需要更多儲存空間。
- 根據查詢執行量,成本可能上升。
- 需依賴現代化的資料基礎設施。
Python 實作範例
以下以 Python 展示 ETL 與 ELT 的基本流程。為簡化示範,我們使用 CSV 檔作為資料來源,pandas 處理轉換,並以 SQLite 資料庫作為目標。
圖片下方的文字描述或說明。
ETL 範例
import pandas as pd
import sqlite3
# 步驟 1:Extract
df = pd.read_csv("sales_data.csv")
# 步驟 2:Transform
df["total"] = df["quantity"] * df["price"]
df_clean = df[["order_id", "customer_id", "total"]]
# 步驟 3:Load
conn = sqlite3.connect("warehouse.db")
df_clean.to_sql("sales", conn, if_exists="replace", index=False)
print("ETL 流程完成:資料已載入 warehouse.db")
ELT 範例
import pandas as pd
import sqlite3
# 步驟 1:Extract & Load
df = pd.read_csv("sales_data.csv")
conn = sqlite3.connect("warehouse.db")
df.to_sql("raw_sales", conn, if_exists="replace", index=False)
# 步驟 2:Transform(於資料庫內執行)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE sales AS
SELECT order_id, customer_id, quantity * price AS total
FROM raw_sales;
""")
print("ELT 流程完成:轉換在資料庫內執行")
從以上例子可看出,ETL 會在載入前進行資料轉換,而 ELT 則是先載入原始資料,再於資料倉儲中完成轉換。
實際應用案例
- ETL: 金融報表、法規遵循、或需在儲存前進行嚴格驗證的系統。
- ELT: 雲端分析、機器學習管線、IoT 資料收集、或以 BigQuery、Snowflake 為核心的大數據分析。
例如,一家銀行可能使用 ETL 以確保合規性資料的正確性;而串流平台則可透過 ELT 即時分析用戶行為。
業界與社群觀點
在資料工程社群中,關於 ETL 與 ELT 的討論不斷。有些專家主張混合策略:在基礎層使用 ETL,之後以 SQL 方式在倉儲中進行 ELT。正如 Reddit 上一位用戶所言:「我喜歡先用 ETL 處理基礎層,再以 SQL 建立衍生層。」這說明實際應用中,兩者往往並行存在。
最佳實踐與建議
- 當轉換邏輯複雜或需先處理再儲存時,使用 ETL。
- 當資料規模龐大或倚重雲端平台時,採用 ELT。
- ELT 模式下需監控查詢效能與成本。
- 可使用 Apache Airflow、dbt、Prefect 等工具來管理資料管線。
- 設計管線時,應考量可擴充性、維護性與透明度。

結語
ETL 與 ELT 是現代資料生態系中不可或缺的兩大模式。ETL 著重於前置處理與控制,而 ELT 則運用雲端運算力量以靈活應對龐大資料。實際上,多數企業會根據應用場景與基礎架構混合使用兩者,以取得最佳平衡。
透過了解差異、學習 Python 實作、並遵循最佳實踐,你將能建立高效、可擴充且具前瞻性的資料管線。