使用 Prefect 的 Python ETL:現代化的 Airflow 替代方案
Prefect 與 Airflow:快速比較
在編排複雜工作流程時,Apache Airflow 多年來一直是首選方案。然而,隨著資料工程需求演變,像 Prefect 這類更新穎的工具逐漸受到青睞,成為更現代化且靈活的替代方案。Airflow 與 Prefect 都旨在管理工作流程,但它們在方法上有所不同,適用於不同的情境。以下是主要差異:
- 易用性:Prefect 的設計以使用者體驗為核心,其語法比 Airflow 更直覺。Airflow 依賴 DAG(有向無環圖),學習曲線較陡峭。
- 可靠性與容錯:Prefect 會在任務失敗時自動重試,並提供集中化的錯誤處理,對生產環境尤為重要。Airflow 也支援重試,但 Prefect 的模型更靈活。
- 彈性:Prefect 允許使用 Python 代碼定義動態工作流程,可輕鬆實現條件邏輯、迴圈與動態映射任務。Airflow 在這方面較有限。
- 可擴展性與雲端整合:Prefect 可無縫整合 Prefect Cloud,提供即時監控、協作工具以及自動擴展,而不需自行管理基礎架構。Airflow 雖可擴展,但需要更多設定與維護。
什麼是 Prefect?
Prefect 是一款現代化 Python 工作流程編排工具,可輕鬆設計、排程及監控資料管線。它簡化 ETL 工作流程的管理,提高韌性與可擴展性。Prefect 把分散式系統的許多複雜性抽象掉,提供簡單方式處理任務依賴、重試、日誌與監控。
與 Airflow 等其他工具的主要差異之一,是 Prefect 的「Flow」模型,每個工作流程任務獨立執行,易於擴展與管理。
開始使用 Prefect
使用 Prefect 的第一步是安裝套件,可透過 pip:
pip install prefect安裝後,可先建立一個簡單的「Hello World」Flow:
from prefect import task, Flow
@task
def say_hello():
# 輸出問候訊息
print("Hello, Prefect!")
with Flow("hello-flow") as flow:
say_hello()
# 執行 Flow
flow.run()
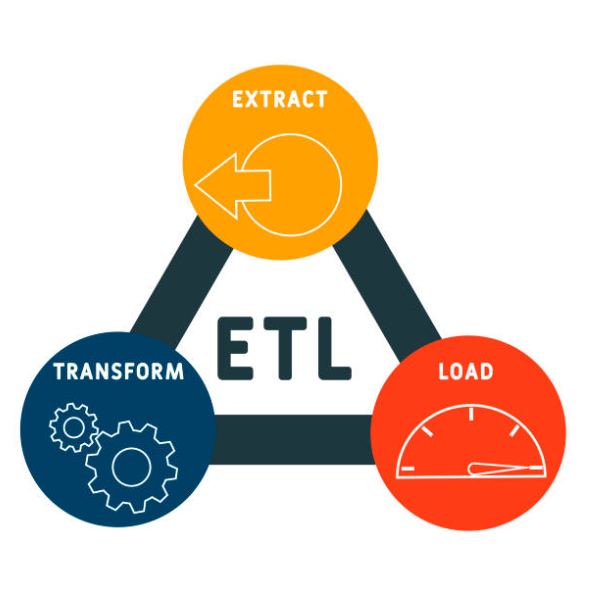
使用 Prefect 建立 ETL 管線
ETL(Extract, Transform, Load)是資料工程工作流程的核心。以下展示如何使用 Prefect 建立 ETL 管線。
ETL 通常包含三個階段:
- Extract(提取):從資料來源(如資料庫或 API)取得資料。
- Transform(轉換):將資料轉換成目標格式或聚合資訊。
- Load(載入):將處理後的資料存入資料倉儲或檔案系統。
在 Prefect 中,每個階段都可定義為任務:
from prefect import task, Flow
@task
def extract_data():
# 模擬資料提取
return {'data': [1, 2, 3, 4, 5]}
@task
def transform_data(data):
# 模擬資料轉換:數值加倍
return [x * 2 for x in data]
@task
def load_data(data):
# 模擬資料載入到資料庫或檔案系統
print(f"資料已載入: {data}")
with Flow("ETL-pipeline") as flow:
data = extract_data()
transformed_data = transform_data(data)
load_data(transformed_data)
# 執行 Flow
flow.run()
處理失敗與重試
Prefect 強大的功能之一是自動處理任務失敗與重試。你可以輕鬆設定任務失敗後的重試策略:
import random, datetime
from prefect import task
@task(max_retries=3, retry_delay=datetime.timedelta(seconds=10))
def extract_data():
# 模擬提取失敗
if random.random() < 0.5:
raise ValueError("資料提取失敗")
return {'data': [1, 2, 3, 4, 5]}
上述範例中,extract_data 任務若失敗會自動重試最多三次。此功能可確保臨時性問題不會導致整個工作流程失敗,使 ETL 管線更可靠。
ETL 最佳實踐
儘管 Prefect 簡化了建立 ETL 管線的過程,但遵循最佳實踐仍非常重要,以確保工作流程可靠且可擴展。